The number of intervals specifies the number of bins into which the input data will be sorted, and can be set in the Input Options dialog of the Input menu. These bins are used only for continuous distributions; discrete distributions are collected at integer values. If the input data is forced to be treated as discrete, this choice will be grayed. Note that the name intervals is used in Stat::Fit to represent the classes for continuous data in order to separate its use from the integer classes used for discrete data.
The number of intervals are used to display continuous data in a histogram and to compare the input data with the fitted data through a chi-squared test. Please note that the intervals will be equal length for display, but may be of either equal length or of equal probability for the chi-squared test. Also, the number of intervals for a continuous representation of discrete data will always default to the maximum number of discrete classes for the same data.
The five choices for deciding on the number of intervals are:
Auto:
Automatic mode uses the minimum number of intervals possible without losing information. Then the intervals are increased if the skewness of the sample is large
Sturges:
Sturges mode is an empirical rule for assessing the desirable number of intervals...If N is the number of data points and k is the number of intervals, then
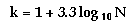
Lower Bounds:
Lower Bounds mode uses the minimum number of intervals possible without losing information. If N is the number of data points and k is the number of intervals, then
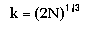
Scott:
Scott mode is based on using the Normal density as a reference density for constructing histograms. If N is the number if data points, sigma is the standard devistion of the sample, and k is the number of intervals, then
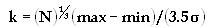
Manual:
Manual mode allows arbitrary setting of the number of intervals.

